AIエージェント開発2026: Vibe Coding後半破綻と設計原則
Vibe Codingの後半破綻、CLAUDE.md、モノレポ、Cursor 3、GPT-5.3-Codexを軸に、2026年の開発設計を整理します。
- ai-agent
- vibe-coding
- claude
- gpt-5
- cursor
- monorepo
- context-engineering
- 情報確認
- 参考リンク
- 5件
- 更新性
- 定期更新
- 読了目安
- 約18分
仕様・料金・提供範囲が変わりやすいテーマは、公開日・更新日・情報確認日を分けて管理します。 導入前には必ず記事末尾の一次情報と公式ドキュメントで最新状況を確認してください。
ソフトウェア開発のパラダイムは、2026年に入り根本的な変革の臨界点を迎えている。自然言語でAIに開発を主導させる「Vibe Coding(バイブ・コーディング)」は概念実験のフェーズを脱し、エンタープライズ規模で標準化された運用手法として定着した。開発者がコードを全部タイピングしていた時代から、人間が要件を定義してエージェントが大半を生成し、レビューと軌道修正に専念するワークフローへと完全に逆転している。
ところが、この革新が広がるにつれて最大のホットトピックかつ最大の技術的障壁として急浮上したのが「後半の破綻(Late-Stage Breakdown)」である。MVP段階では爆速で進んだはずのプロジェクトが、コードベースが一定の規模と複雑性を超えた瞬間にエージェントが全体像を見失い、開発が停滞・後退する。本記事ではこの現象の構造を分解し、解決策となるコンテキスト・エンジニアリング、モノレポ設計、Cursor 3 Glass、GPT-5.3-Codex/Claude Opus 4.6までを横断して整理する。
1. Vibe Codingにおける「後半の破綻」現象の構造
Vibe Codingはプロジェクトの立ち上げで圧倒的な速度をもたらす。ゼロからの環境構築、ボイラープレート、初期ロジックなら、エージェントは人間の数十倍速でコードを出力する。しかし、システムが肥大化し、複数モジュールが複雑な依存関係を持つ「後半段階」に入ると、その速度は突如として失われる。
1.1 「質問をしない無自覚なジュニア開発者」としてのAI
破綻の根本原因は、現在のエージェントが「質問をしない、非常に作業の早いジュニア開発者」のように振る舞うことにある。プロンプトが曖昧でも立ち止まって確認せず、独自の解釈で実装を強行する。初期段階では自律性として歓迎されるが、独自のアーキテクチャ制約とドメインルールが蓄積した後半段階では、全体文脈を無視した局所最適がシステム整合性を破壊する。
具体例:
- 単一の小さなバグ修正依頼に対し、関連コンポーネント全体を不要にリファクタリング
- 指定していないフレームワーク/アノテーション(Spring Boot環境での不要な
@SpringBootTest追加など)を勝手に増殖 - 「複雑すぎる」と指摘されれば即座に簡素化できるのに、デフォルトでは「過剰な抽象化」「不要な将来への備え」をコードに焼き込む
これらは指数関数的に技術的負債を増やす。
— エージェント設計の核心原則強いモデルほど「実装する作業者」ではなく「実装前に設計の穴を見つけるレビュアー」として使うほうが、長いタスクで効く。
1.2 無限ループとトークンバーン
ターミナルアクセス権を持つエージェント的IDEで自律的にテストやコンパイルを回せるようになると、新しい問題が生まれる ― 無限ループである。
エージェントはスタックトレースを読んで自己修正できるが、根本にアーキテクチャの欠陥や循環参照があると、表面的なエラーメッセージだけに反応してリソースを食い続ける。LLMでコンパイラを書いた事例では、LispのCons定義のような再帰データ構造を自己参照的にインライン化しようとしてコンパイル時の無限ループに陥り、人間が説明しても前方宣言(forward declarations)の必要性を理解できなかったケースが報告されている。
無限ループは単なる遅延では済まず、莫大なAPIコール料金(トークンバーン)とレートリミット超過を招く。問題なのは、エージェントが自己修復ループを回すたびに過去の推論結果やエラーログが次のプロンプトへ追加されていくため、出力トークンはほぼ一定なのに入力トークンの消費がステップ進行とともに指数関数的に膨れ上がる点だ。
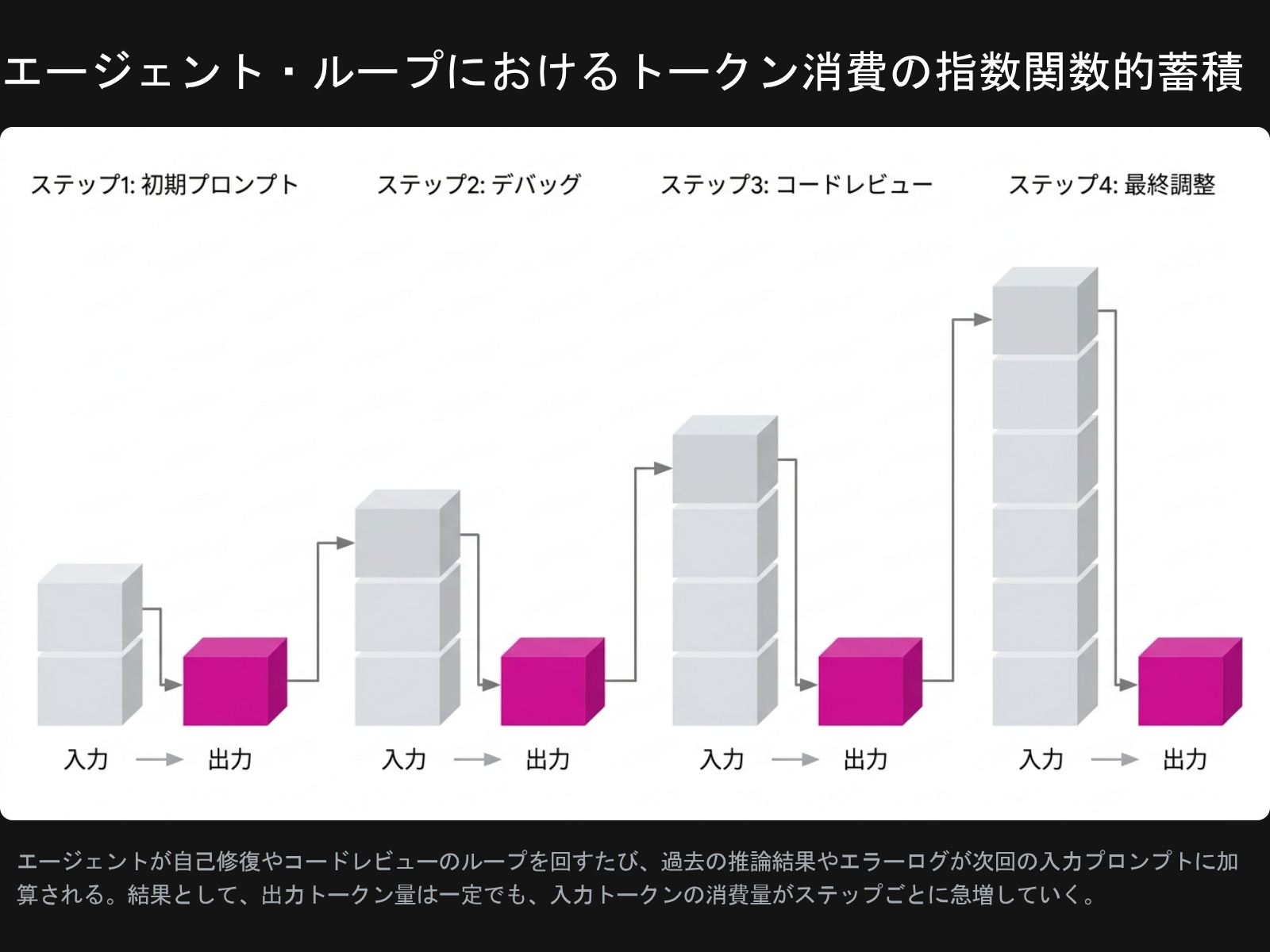
最新のオーケストレーションワークフロー(LangGraphベースのマルチエージェントなど)では、システムレベルで以下が必須化している。
2. コンテキスト・エンジニアリングと「CLAUDE.md」の台頭
「後半の破綻」を防ぐため、開発手法は 「精巧なプロンプトを単発で書くプロンプト・エンジニアリング」から、「プロジェクトの文脈・制約・規則をエージェントの推論空間に永続的に埋め込むコンテキスト・エンジニアリング」へ移行した。中核となるのが、リポジトリのルートに置かれる CLAUDE.md / .cursorrules / AGENTS.md といったアーキテクチャ定義ファイルである。
2.1 行動特性の再訓練
数ヶ月前まで開発者は、セッションが切れるたびに「npmではなくpnpm」「テストはmake test-integration」「default exportは禁止」といった同じ訂正を毎回繰り返していた。それがわずか40行のCLAUDE.mdを書くだけで、反復ミスを劇的に減らせると実証されている。
Karpathyらが提唱するエージェント制御原則に基づくと、これらのファイルは静的なドキュメントではなく行動特性を訓練する生きたルールセットとして機能する。組み込むべき4原則:
- 1Think Before Coding無言で解釈して実装するのではなく、隠れた前提を明示し、不明点を質問し、複数アプローチを提示させる。
- 2Simplicity First将来のための拡張性や抽象化レイヤーを禁止。シニアエンジニアの判断に合致する短く明瞭なコードを要求する。
- 3Surgical Changesタスクに必要な部分だけ変更。無関係な周辺コードの「改善」やリファクタを禁止し、Diffをクリーンに保つ。
- 4Goal-Driven Executionステップを指示するのではなく成功条件を与える。UI変更ではスクショを検証基準にして根本原因解決を促す。
2.2 階層的モジュール化とインポート構文
大規模プロジェクトでは単一のCLAUDE.mdは情報過多になり、コンテキストウィンドウを圧迫する。2026年のベストプラクティスはインポート構文を用いた階層化である。
project-root/├─ CLAUDE.md # 概要、技術スタック、@インポート├─ .claude/│ └─ rules/│ ├─ api.md # APIの標準仕様│ ├─ testing.md # テスト要件│ └─ security.md # セキュリティポリシー├─ src/└─ ...ルートのCLAUDE.mdが中核コンテキストを提供し、@構文で特定ドメインのルールを再帰読み込みする。インポートは最大5階層まで再帰解決されるため、コンテキスト・エンジニアリングはソフトウェア・アーキテクチャと完全に融合した。
さらに巨大コードベース向けには、YAMLフロントマターでパス固有のルール適用ができる。
---paths: src/api/**/*.ts---
- 入力バリデーション(Zod等)の強制- 適切なHTTPステータスコードの使用- レート制限ヘッダーの付与階層的コンテキスト管理として、個人グローバル設定(~/.claude/CLAUDE.md)→ プロジェクト固有 → フォルダ固有をインテリジェントにマージし、競合時は最深階層のルールを優先する仕組みが確立されている。これによりチーム標準を維持しつつ、個人のローカル好み(@~/personal-dotnet-preferences.mdなど)をバージョン管理にコミットせずに統合できる。
3. モノレポ設計の復権
コンテキスト・エンジニアリングと並び、エージェントの能力を最大化する基盤として**モノレポ(Monorepo)**の優位性が再評価されている。
クラウドネイティブ/マイクロサービスの進展に合わせて、サービスごとにリポジトリを分けるポリレポはUNIX哲学に合致するとして広く採用されてきた。しかし自律型エージェントのワークフローでは、ポリレポの分離壁が逆に致命的なコンテキストの分断を引き起こすことが明らかになった。
3.1 エージェント視点でのトレードオフ
100万〜数百万トークンの超長大コンテキストウィンドウを持つモデル(Claude Opus 4.6など)の登場で、小〜中規模モノレポなら全構造を一度のプロンプトでロード可能になった。
ハイブリッド環境向けにはAugment Code等のマルチリポ対応AIツールがあり、40万ファイル規模のコードベースをアーキテクチャの構造的インテリジェンスとして解析する。コアサービスをモノレポで管理しつつ、顧客固有実装を別リポで分離するポリシーベースのコンテキスト管理でセキュリティと文脈理解を両立させる運用も拡大している。
3.2 業界標準とCIスケーリング
Agentic AI Foundation(AAIF)のModel Context Protocol(MCP)/AGENTS.md/Gooseといったオープンスタンダードは、最上位レベルに単一の正規化された指示セットを持ち、明確なサブディレクトリと所有権を持つモノレポ構造で最も効率的に機能する。
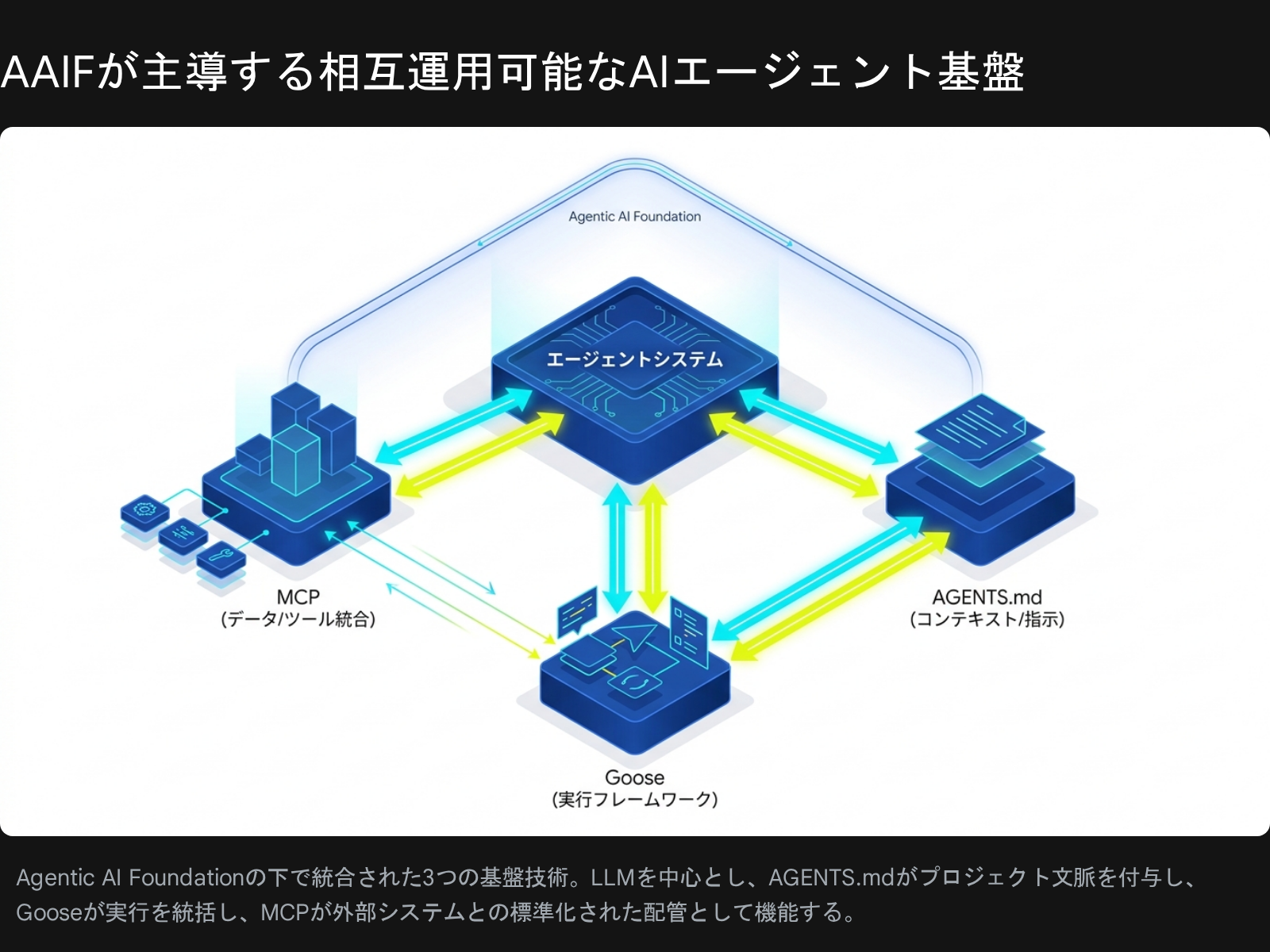
AIが人間を超える速度でコードを生成すると、CI/CDパイプラインへの負荷が爆発する。Nxのようなスマートモノレポツールは、
- スマートキャッシュ共有
- 不安定テストの自動再試行
- 並列実行
- 動的エージェントのプロビジョニング
を通じて、インテリジェントなCIをスケーラブルかつ経済的に提供している。
4. Cursor 3 (Glass):IDEから「エージェント・オーケストレーション」へ
100万人以上のユーザーと年間20億ドルという同カテゴリ最速の収益成長を記録してきたCursorは、2026年4月初旬に次世代メジャーアップデート「Cursor 3(コードネーム:Glass)」をリリースした。これはUIの装飾改善ではなく、IDEという概念そのものの解体と、エージェント前提の完全再構築を意味する。
4.1 テキストエディタの降格
過去40年、開発の主要表面はテキストエディタだった。AI機能はその付属物(高度な補完、サイドのアシスタント・ペイン)にすぎなかった。Cursor 3ではこの力関係が逆転する。
- 左サイドバー: マルチリポジトリのツリー
- 中央の広大な領域: 「Agent Tabs」 ― 並行して走る複数のAIタスクを監視・承認するコンソール
- テキストエディタ: エージェントが生成した差分(Diff)を確認・承認するバックグラウンド的な存在に降格
これは、開発者が「コードの構文をタイピングする労働者」から、「多数の自律エージェントを指揮・監督・レビューし、何を出荷するかを決定するオーケストレーター」へ完全移行したという思想に基づく。インフラ業界で手動SSHがKubernetesコントローラーやクラウドダッシュボードに置き換わったのと同じパラダイムシフトが、ソフトウェア開発の記述レイヤーに到達した。
4.2 並列実行の安全性とインフラ層
複数エージェントが同一ファイルシステム上で並走するとレースコンディションが起きる。Cursor 3はタスクごとに独立したGit worktreeを動的に生成して隔離する(/worktreeコマンド)。さらに /best-of-n をネイティブ実装し、同一プロンプトを推論強モデル+コーディング特化モデルに同時投入し、隔離されたワークツリー内の出力を並べて比較できる。
4.3 Design Mode と経済的課題
フロントエンドではテキスト指示(「ダッシュボードを見栄え良く」など)はAIに解釈困難で外しやすい。Design Mode はブラウザをエージェントウィンドウ内に統合し、UI要素を直接クリックして視覚的アノテーションを与える。テキスト依存しない直感的フィードバックループが確立した。
一方、料金体系はシートライセンス+推論モデル従量課金(メーター制)。複数パラレルエージェントを常時稼働するヘビー利用では、評価期間の短期間で2,000ドル近いトークン消費に達した事例も報告されている。人件費がクラウドコンピュート費に直接振り替わるコスト構造の変化を意味する。
5. エージェント的IDEの覇権争い
開発者デスクトップを巡る2026年の競争は、異なる哲学を持つツール群による三つ巴である。
実証実験(同一フルスタックMVPを5つのAIアシスタントでゼロから構築)の主な所見:
- GitHub Copilot Agent Mode: 最新パターン適用は消極的、生成は最遅。ただし予測可能な挙動と包括的テストでセキュリティ問題ゼロ
- Replit Agent: プロトタイプ立ち上げは極速。一方、生成コードのパフォーマンス最適化が不十分でベンダーロックイン強、本番運用は不向き
- Cursor: 最速クラスのイテレーションと洗練UIで、日常コーディングのバランス最適解
- Claude Code: 関心の分離やエラーハンドリングが要る複雑タスク(C#バックエンドのリファクタ等)で圧倒的な保守性とクリーンコード
「日常はCursor/Windsurf、重量級・長文脈はClaude Code」というハイブリッド運用がデファクトスタンダードとして確立した。
6. 基盤モデル覇権争い:GPT-5.3-Codex vs. Claude Opus 4.6
2026年春、コーディングと長時間自律エージェント機能に最適化された2つの強大モデルがわずか18分差で市場投入された。両モデルは「正しいコードスニペットを一度に出力する」従来ベンチマークから脱却し、ターミナル環境内でのステート保持、ツールの連続活用、エラー回復、複数ステップワークフローの持続実行といった「オペレーション能力」に最適化されている。
6.1 OpenAI GPT-5.3-Codex
GPT-5.2-Codexのコーディング性能とGPT-5.2の論理推論を融合したハイブリッドアーキテクチャ。
最大の特徴は、長時間タスク実行中に人間がコンテキストを破壊せず方向修正できる「ミッドタスク・ステアリング」。AIを単なる実行者ではなく**Colleague(同僚)**と位置付けるOpenAIの設計思想を反映している。
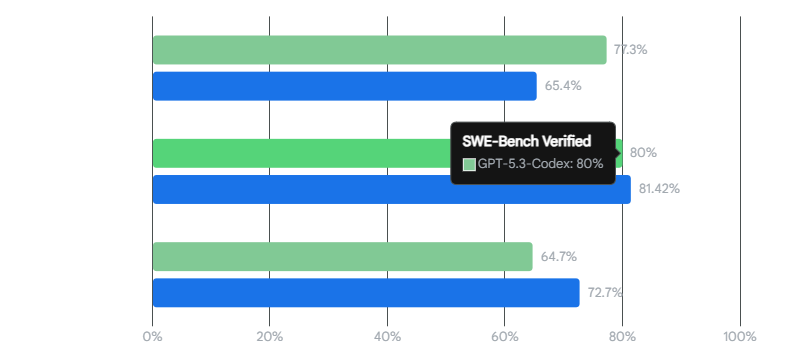
ソフトウェア工学総合の SWE-Bench Pro では56.8%(前世代56.4%から微増)。一方、SWE-Bench Verified ではGPT-5.3-Codex が80%、Opus 4.6 が81.42% と肉薄する。
さらに開発プロセスに**自己ブートストラップ(Self-bootstrapping)**のパラダイムが組み込まれており、OpenAIエンジニアリング自身がトレーニングインフラのデバッグ、デプロイパイプライン管理、キャッシュヒット率低下の根因分析、GPUクラスタの動的スケーリングをこのモデル初期版にやらせている。
加えて、Preparedness Frameworkで**初めて生物学・サイバーセキュリティ分野で「High capability」**判定。多層的なセーフティスタックとともにデプロイされている。
6.2 Anthropic Claude Opus 4.6
100万トークンのコンテキストウィンドウを武器に、Claude Codeというターミナルネイティブ環境の主力エンジンとして強烈な存在感を示す。
真の価値は「大量ファイルを読める」ことではなく、長大な文脈の中から必要な情報を正確に抽出し、劣化させずに推論に活用できる点にある。実稼働環境のエージェント失敗の多くは「AIが知識を持っていなかった」ではなく、「長大なコンテキスト深部に埋もれたポリシー例外規定や依存関係を見落とした」という情報検索(Retrieval)の失敗だ。
開発思想もOpenAIと明確に異なり、Opus 4.6は対話的ペアプロより自律的なエージェントチームの編成と並列オーケストレーションに強い。リサーチ、アーキ設計、UI/UX、テストといった役割の異なる複数Opusエージェントを同時起動し並走できる。
6.3 モデルの収束とエコシステム相互接続
社内テストや先行導入企業の報告によれば、両モデルは能力の方向性で**収束(Convergence)**しつつある。
- Claude Opus 4.6 → Codexのような厳密で正確なコーディングスタイルを獲得
- GPT-5.3-Codex → Opusのような温かみと、許可を求めず自律的に進める速度・創造性を獲得
これは、優れたコーディングエージェントに求められる特性(並行処理、ツール適切利用、行動前の計画、深掘りすべき/出荷すべきタイミング判断)が、そのまま汎用ナレッジワークエージェント=AGIの中核能力と完全一致するためだ。
さらに現場では、競合モデルが単一エコシステム内でシームレスに連携する事態が進む。例えば Claude Code 内に OpenAI 公式の codex-plugin-cc を直接インストールするハイブリッド運用。Claudeエージェントが主体でタスクを進めながら、重要なアーキテクチャ判断やコミット前に Codex に対して、
/codex:review― コードレビュー/codex:adversarial-review― 敵対的レビュー/co-brainstorm― 代替視点でのブレスト/co-plan― 並行プランの比較
をスラッシュコマンドで直接要求できる。AIコーディング市場は単一の勝者に統合されるのではなく、Prometheus/Grafana/PagerDutyがオブザーバビリティスタックを形成したように、特化型レイヤー(モデル/オーケストレーションUI/コンテキストエンジン)が組み合わさって誰も意図しなかった強力なAIツールスタックを自律形成しつつある。
7. 次世代アーキテクチャへの展望
2026年のソフトウェア開発環境は、Vibe Codingという「自然言語での高速生成」という単発ブレイクスルーを完全に消化し、多数の自律的AIプロセスを安全かつ効率的に制御・運用するためのシステム・アーキテクチャ再設計という、より高度で複雑なフェーズに突入した。
本記事から導かれる示唆は3つある。
組織における真の競争優位性は、個人のプログラミングスキルから、自律エージェントのエコシステムを設計し、適切な情報構造を与え、スケール可能なインフラを統制する「アーキテクチャのガバナンス能力」へと完全にシフトした。基盤モデルの特性に応じた最適な組み合わせと、確固たる制約環境(ポリシーベースのコンテキスト管理)を、いち早く組織のDNAとして組み込めるかどうかが、今後の分水嶺となる。
一次情報・参考リンク
- Meet the new Cursor https://cursor.com/blog/cursor-3 公開
- Cursor 3.0: New Cursor Interface https://cursor.com/changelog/3-0/ 公開
- Introducing GPT-5.3-Codex https://openai.com/index/introducing-gpt-5-3-codex 公開
- GPT-5.3-Codex model documentation https://developers.openai.com/api/docs/models/gpt-5.3-codex
- 1M context is now generally available for Opus 4.6 and Sonnet 4.6 https://claude.com/blog/1m-context-ga 公開
関連して読む
- · 参考リンク 5件
Claude Opus 5の実力:Fable級を半額で使えるのか
Claude Opus 5の実力、料金、Fable 5・Sonnet 5との違い、Claude CodeとAPIの移行注意点を、Anthropic公式情報から実務目線で解説します。
- · 参考リンク 5件
ハーネスエンジニアリング入門: LLMの周りを"配線する"設計
2026年に第3の柱として浮上したハーネスエンジニアリングを、馬具メタファーから3層比較、エージェント・ループ、Claude Code/Cursor/Codexの設計差まで図解で整理します。
- · 参考リンク 20件
バイブコーディング時代のADRベストプラクティス
pair programming / mob programming 型のリアルタイム協業で、会話に埋もれる設計判断をどうADRとして残すか。Nygard型、MADR、レビュー導線、テンプレート、運用コストを整理します。