政府AI「源内」OSS公開: 公開範囲と未公開部分
デジタル庁が公開したガバメントAI「源内」のソースコード、ライセンス、未公開部分、自治体・民間導入時の注意点を整理します。
- government-ai
- gennai
- oss
- digital-agency
- rag
- japan
- 情報確認
- 参考リンク
- 6件
- 更新性
- 定期更新
- 読了目安
- 約14分
仕様・料金・提供範囲が変わりやすいテーマは、公開日・更新日・情報確認日を分けて管理します。 導入前には必ず記事末尾の一次情報と公式ドキュメントで最新状況を確認してください。
2026年4月24日、デジタル庁はガバメントAI「源内」の一部を、GitHub上で無償のOSSとして公開した。公式発表で明記されている公開対象は、源内のWebインターフェース部分のソースコードと構築手順、そして源内で使われている一部AIアプリの開発テンプレート・実装である。公開開始日は令和8年、すなわち2026年4月24日。ライセンスは「商用利用可能」と説明されており、地方公共団体、政府機関、民間企業による再利用・改変・サービス化を念頭に置いた公開だ(デジタル庁)。
結論:これは「政府製AIモデルの公開」ではなく、「行政向け生成AI基盤の参照実装公開」である
今回の公開を正確に理解するうえで最も重要なのは、 「源内そのもののすべて」や「政府が使っているLLM」が公開されたわけではない という点だ。公開された中心は、職員がAIアプリを使うためのWebインターフェースと、行政実務用AIアプリを構築するためのテンプレート群である。デジタル庁の公式noteでも、公開対象はWebインターフェースのソースコード・構築手順と、一部AIアプリの開発テンプレート・実装であり、内部マニュアル、権利を保有しないLLM・書籍、稼働中の生ログなどは公開しないと説明されている(デジタル庁note)。
その意味で、今回の公開は「政府がAIモデルをオープンソース化した」というより、「政府・自治体・民間が安全な生成AI利用環境を構築するための土台を、再利用可能なソフトウェア資産として公開した」と見るのが正確だ。
そもそも「源内」とは何か
源内は、デジタル庁が開発・運用する生成AI利活用基盤で、政府職員が業務特化の生成AIアプリケーションを迅速・安全・簡単に利用できる環境として位置づけられている。デジタル庁の政策ページでは、ガバメントAIとは政府職員が安全・安心にAIを活用できる基盤であり、その第一歩として生成AI利用環境「源内」を各府省庁に展開していると説明されている(デジタル庁 政策ページ)。
この取り組みは、2025年5月成立のAI法と、同年12月に閣議決定されたAI基本計画を背景にしている。政府自らが先導的にAIを利活用する「隗より始めよ」の方針のもと、2026年度中には全府省庁約18万人の政府職員が源内を利用可能にする計画が示されている。
デジタル庁は2026年3月6日にも、2026年5月から2027年3月まで、全府省庁約18万人の政府職員を対象に源内の大規模実証を行う予定を公表している。大規模実証では、単に生成AIを配るのではなく、業務プロセス、働き方、組織文化の変革を伴う導入として、各府省庁の利活用促進とガバナンス強化も求められている(デジタル庁 大規模実証)。
公開された2つのリポジトリ
公開場所は、デジタル庁のGitHub公式アカウント上の2リポジトリである。1つ目は genai-web、すなわち源内Web、AIインターフェース部分。2つ目は genai-ai-api、すなわち源内AIアプリである。デジタル庁の発表では、この2つが公式リポジトリとして案内されている。
genai-web は、利用者が直接触るWebアプリケーションである。READMEによれば、AWSのオープンソース「Generative AI Use Cases(GenU)」をベースにしつつ、チーム管理機能、AIアプリ管理機能、外部マイクロサービスとして構築した生成AIアプリの追加・実行機能、デジタル庁デザインシステムの適用、アクセシビリティ試験、監視・モニタリングなどの運用機能を追加している。
genai-ai-api は、行政実務用AIアプリのリポジトリである。READMEでは、源内は大きく「源内Web」と「行政実務用AIアプリ」の2種類のシステムで構成され、このリポジトリでは中央省庁で実際に展開されている行政実務用AIアプリの一部を公開していると説明されている。
公開されたAIアプリ/テンプレートの中身
公開されたAIアプリ側の実装は、AWS、Azure、Google Cloudの3系統に分かれている。これは単なるサンプル集というより、行政実務向けAIアプリを各クラウド上でどう構築するかを示す実装例に近い。
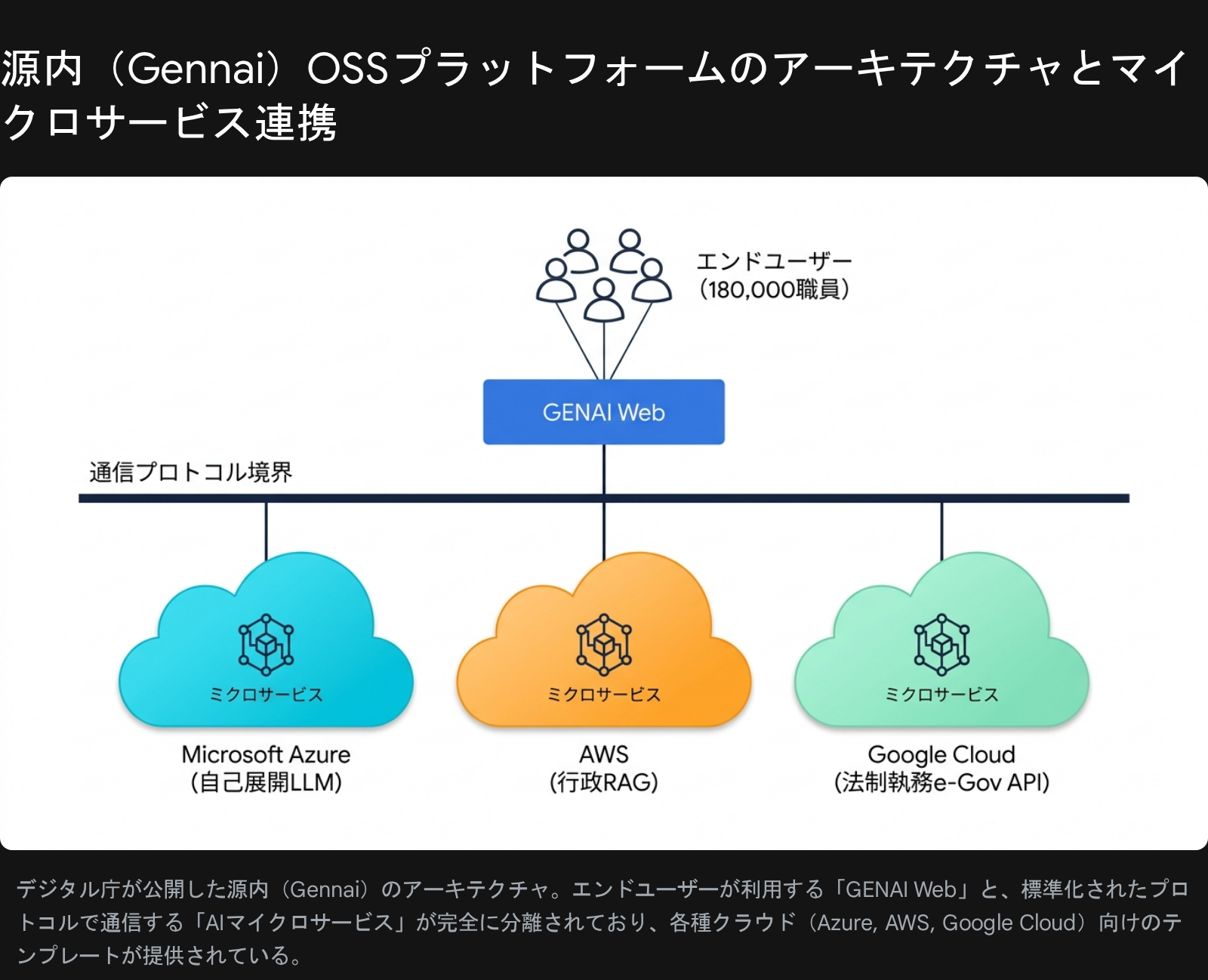
源内のアーキテクチャは、エンドユーザーから見える GENAI Web と、標準化されたプロトコルで接続される「AIマイクロサービス」が完全に分離されている。AWS / Azure / Google Cloud 各クラウド向けにテンプレートが用意され、行政実務に必要な機能ごとに別系統で配備できる構造だ。
| 区分 | 公開内容 | 技術的な中身 |
|---|---|---|
| AWS | 行政実務用RAGの開発テンプレート | AWS CDK、Bedrock Knowledge Base、OpenSearch Serverless、S3、API Gateway、Lambdaなどを使うクエリ拡張RAG |
| Azure | LLMをセルフデプロイして利用する開発テンプレート | vLLM対応モデルやAzure OpenAIモデルをAzure上でホスティングし、APIM、Application Gateway、VMSS、Azure FunctionsなどでAPI提供 |
| Google Cloud | 最新の法律条文データを参照し回答する法制度AIアプリ | BigQuery MLのベクトル検索、Vertex AI Gemini、Cloud Functions、API Gateway、Terraformを使う法令検索・回答生成システム |
AWS版の Query Expansion RAG API は、Bedrock Knowledge Baseを活用し、クエリ拡張、ナレッジベース検索、関連性評価、回答生成をLambdaで実装する構成だ。API GatewayとLambdaを組み合わせ、x-api-keyヘッダーによる認証を行うAPIエンドポイントを提供する。暗号化ではKMS Customer Managed Encryption Keyを使い、個別CMEK方式と共通CMEK方式の選択も示されている。
Azure版は、vLLMに対応するHugging FaceモデルやAzure OpenAIモデルをMicrosoft Azure上でホスティングし、APIとして提供するためのテンプレートである。構成要素として、Azure API Management、Application Gateway、VMSS/VM、Azure Automation、Azure Functions、Azure OpenAI Serviceなどが挙げられている。vLLM実装例としてPLaMo翻訳モデルも示されているが、利用時には別途PLaMo側のライセンス確認が必要になる(genai-azure README)。
Google Cloud版の Lawsy-Custom-BQ は、法令に関する質問を受け取り、AIが意図を解析してレポートを生成するサーバーレスAPIシステムである。BigQuery MLのベクトル検索とGeminiを組み合わせ、日本の法令データを対象に検索・回答生成を行う。技術スタックとして、Python、Google Cloud Functions、Vertex AI Gemini 2.5 Flash、BigQuery ML、API Gateway、Terraformが明記されている。
源内Webの設計思想:AIアプリを外部REST APIとして差し込む
源内Webの重要な特徴は、外部REST APIとして構築された行政実務用AIアプリを、Webインターフェースから登録・実行できる点にある。AIアプリAPI仕様書では、源内Webは「行政実務用AIアプリ」として外部REST APIを呼び出せると説明されており、チーム管理メニューからAIアプリを登録する際のJSONフォーマットも定義されている。
入力UIはJSON定義に基づいて自動生成される。対応コンポーネントには、text、number、textarea、file、select、checkbox、radio、hiddenが含まれる。実行方式は同期・非同期の両方に対応し、レスポンスはMarkdown対応のテキスト出力やBase64エンコードされたファイル出力を扱える(AIアプリ開発ガイド)。
これは実務上かなり大きい。各自治体やベンダーが「AIアプリ本体」を独自に作っても、源内Webが共通フロントエンド、認証、チーム管理、履歴、入力フォーム生成の役割を担えるからだ。つまり、AIアプリを個別にフルスクラッチのWebサービスとして作る必要が薄れ、外部APIとして差し込む方式に寄せられる。
汎用AIと行政実務用AIの違い
源内Webでは、デプロイ直後から使える汎用的なAIアプリと、別途AI環境に登録する行政実務用AIアプリが分かれている。汎用的なAIアプリには、チャット、文章生成、翻訳、画像生成、ダイアグラム生成が含まれる。行政実務用AIアプリは、政府共通の大規模データセットや各府省庁の独自データなどをもとに構築され、チーム単位で登録され、同じチームのユーザーのみが利用可能と説明されている(AIアプリの種類)。
この設計は、行政や大企業のように「部署ごとに扱えるデータが違う」「同じAI基盤でもアクセス範囲を分けたい」という組織に向いている。単なるチャット画面ではなく、組織内の権限・チーム・アプリを束ねるAI利用基盤として作られている点が、今回の公開物の価値だ。
ライセンス:商用利用は可能。ただし注意点がある
ソフトウェア部分は MIT License で公開されている。MIT Licenseは、利用、複製、改変、公開、配布、サブライセンス、販売を広く認める permissive license であり、今回の「商用利用可能」の根拠になる。ただし、著作権表示と許諾表示を含める必要があり、ソフトウェアは無保証で提供される。
一方、ドキュメント、画像、図表はCreative Commons Attribution 4.0 International、すなわち CC BY 4.0 で公開されている。これは再利用可能だが、出典表示などの表示義務がある。また、CC BY 4.0には、利用者がデジタル庁から後援・承認・公式地位を得ているかのように示すことを許すものではない、という趣旨の「No endorsement」条項も含まれる。
さらに、genai-webにはAWS Prototyping Program由来の一部Lambda・CDKファイルがあり、これらはAmazon Software Licenseの対象とされている。 ASL対象ファイルはAWS以外では利用できない と明記されており、非AWS環境で源内を動かす場合は該当箇所を自環境向けに実装し直す必要がある(ASL対象ファイル)。
したがって、「商用利用可能」は正しいが、「何も考えずに全ファイルを全クラウドで自由に使える」という意味ではない。実務上は、MIT部分、CC BY 4.0部分、ASL対象部分、依存ライブラリ、利用するLLMやデータセットのライセンスを分けて確認する必要がある。
公開されていないもの
デジタル庁の公式noteは、公開しないものとして、
- 実際の源内で利用している行政実務用RAG等が参照する内部マニュアル類
- デジタル庁が権利を保有しない大規模言語モデルや書籍
- 稼働中の源内の生ログ
を挙げている(デジタル庁note)。
これは当然の線引きだ。内部マニュアルや職員の利用ログまで公開すれば、機密性、個人情報、著作権、セキュリティの問題が出る。今回公開されたのは、あくまで「基盤を再現・参照するためのコードとテンプレート」であって、政府内部の知識ベースや運用データではない。
なぜ公開したのか:重複開発の防止と、官民共創
デジタル庁は、源内の一部をOSSとして公開する目的として、地方公共団体や政府機関における類似AI基盤の重複開発を防ぎ、社会全体の開発コスト削減に貢献することを挙げている。また、OSSは改変・再利用が可能なため、特定事業者やサービスへの依存を抑え、各機関が自らの要件に応じてAI基盤を運用・発展させられるとも説明している。
民間企業に対しても、源内OSSをベースに独自のアイデアや技術力を加えたサービスを開発・提供できるとしている。特に地方公共団体向けAIサービス市場の活性化、中小企業やスタートアップの参入促進、日本全体のAI産業の裾野拡大が狙いとして示されている。
つまり今回の公開は、「国が作った便利ツールを配布した」というだけではない。行政AIの調達仕様、実装標準、UI、AIアプリ連携プロトコル、セキュリティ設計のたたき台を、民間と自治体が共有できるようにした政策的な一手である。
国内LLM政策との関係
源内は、国内LLMの試用・評価の場としても位置づけられている。デジタル庁は2026年3月6日、ガバメントAIで試用する国内LLMについて15件の応募から7件を選定したと発表した(公募結果)。選定されたモデルには、以下が含まれる。
- NTTデータ「tsuzumi 2」
- カスタマークラウド「CC Gov-LLM」
- KDDI・ELYZA共同応募体「Llama-3.1-ELYZA-JP-70B」
- ソフトバンク「Sarashina2 mini」
- NEC「cotomi v3」
- 富士通「Takane 32B」
- Preferred Networks「PLaMo 2.0 Prime」
この流れと今回のOSS公開を合わせると、デジタル庁は「AIモデルの調達・評価」と「AI利用基盤の公開」を並行して進めていることがわかる。前者は政府で使うLLMをどう評価・導入するか、後者はそのLLMやAIアプリをどのような安全な業務基盤で使うか、という役割分担である。
実装面のハードル:すぐに誰でも動かせるわけではない
源内Webのドキュメントを見ると、デプロイ前にはNode.js、AWS CLI、AWS CDK CLI、依存関係のインストール、AWS CDKのBootstrap、jqなどが必要とされている。デプロイ手順では、環境ごとのパラメータファイルを作成し、CDKでデプロイし、CloudFrontのURLまたはカスタムドメインにアクセスしてログイン画面を確認する流れが示されている(事前準備)。
認証面では、複数のSAML認証プロバイダーを使ったログインに対応している。プライマリプロバイダーと追加プロバイダーを分け、アクセスURLのパスによって使用するIdPを切り替える仕組みが説明されている(SAML認証手順)。
ログ送信機能も用意されており、汎用AIアプリログ、行政実務用AIアプリログ、ユースケースビルダーログ、AIアプリ定義情報、実行履歴、Cognitoユーザー情報、Cognitoユーザーアクティビティログなどを任意の収集先に毎日送信できるとされている。送信先APIにはAWS IAM認証、クロスアカウントロール、所定のエンドポイントなどが必要になる(ログ設定)。
これは裏返すと、導入にはクラウド、IAM、SAML、ネットワーク、ログ管理、セキュリティ、個人情報管理の知識が必要だということだ。ソースコードが公開されたからといって、小規模自治体や中小企業がそのまま本番運用できるほど軽いものではない。
コミュニティ型OSSというより「公開された参照実装」に近い
GitHub上のREADMEでは、genai-webもgenai-ai-apiも、サービスの安定運用に影響する致命的な問題に限りIssueを受け付け、Pull Requestは受け付けない方針を示している。報告対象外には、機能追加要望、軽微な表示崩れ、誤字脱字、パフォーマンス改善提案、コーディングスタイル指摘、質問・使い方相談などが含まれる。
そのため、この公開はLinuxやKubernetesのような広範なコミュニティ協働型OSSというより、政府が作った実装を透明化し、自治体・政府機関・民間企業が参照・再利用できるようにする 「公開参照実装」 に近い。コードは自由度の高いライセンスで使えるが、開発プロセス自体がオープンコミュニティ化されているわけではない。
最大の意義:行政AIの「調達仕様」がコードで示された
今回の公開で最も大きいのは、行政AI基盤の要求水準が、抽象的な資料ではなく動くコードとドキュメントで示されたことだ。AIアプリを外部APIとして登録する仕様、同期・非同期実行、Base64ファイル入出力、チーム単位のアプリ利用、SAML認証、ログ収集、RAG、法令検索、LLMセルフデプロイなどが、具体的な実装として公開された。
自治体や省庁がAI基盤を調達するとき、これまでは「安全に使える生成AI環境」「庁内データを参照するRAG」「職員向けAIアプリ管理」といった曖昧な要件になりがちだった。源内OSSを参照すれば、仕様書に「このようなAPI連携」「このようなチーム管理」「このようなログ設計」「このようなRAG構成」といった具体性を持たせやすくなる。デジタル庁自身も、AI基盤に関する調達仕様書を作成する際に源内OSSを参照・指定することでAI実装が容易になると説明している。
民間企業にとっての商機
民間企業にとっては、少なくとも4つの商機がある。
- 自治体向けのマネージド源内導入支援。クラウドアカウント設計、SAML連携、ログ基盤、セキュリティポリシー、運用設計まで含めた導入支援は需要が出やすい。
- 源内Webに接続する行政実務用AIアプリの開発。庁内規程検索、条例・要綱検索、議会答弁支援、住民問い合わせ分類、文書校正、補助金審査補助など、各自治体・各部署に特化したAIアプリをREST APIとして提供できる。
- 調達・監査・ガバナンス支援。源内は単なるAIチャットではなく、機密情報、ログ、認証、アクセス制御、AIアプリの権限管理を含む基盤であるため、導入時には情報セキュリティ、個人情報保護、AIガバナンスの整備が必要になる。
- 国内LLMや業界特化モデルの接続支援。デジタル庁が国内LLMの試用評価を進めていることからも、モデルを「作る」だけでなく、行政業務基盤に「安全につなぐ」技術が重要になる。
導入時の注意点
商用利用を検討する企業や自治体は、少なくとも次の点を確認すべきだ。
1つ目は、 ライセンスの切り分け である。ソフトウェアはMIT、ドキュメント・画像・図表はCC BY 4.0、一部AWS由来ファイルはASLであり、特にASL対象ファイルはAWS以外で使えないとされている。
2つ目は、 モデル・データ・外部APIのライセンス である。AzureテンプレートのPLaMo翻訳モデル例のように、コードのライセンスとは別にモデル側の利用条件が存在する場合がある。
3つ目は、 セキュリティ運用 である。AIアプリ登録手順書では、AIアプリは特定IPからのリクエストのみ受け付けるよう制限され、源内Web側の外部アプリ用IPアドレスをAIアプリ側に登録する手順が示されている。
4つ目は、 メンテナンスの継続性 である。デジタル庁は、脆弱性対応など必要なメンテナンスのため当面は更改・修正作業を継続するが、永続的なメンテナンスを保証するものではなく、将来的にOSS公開を終了する場合があると明記している。
評価:大きな転換点だが、過度な期待は禁物
今回の源内OSS公開は、日本の行政AIにとってかなり大きな転換点である。理由は、政府のAI利用基盤が「ブラックボックスの調達物」ではなく、少なくとも一部は読み、再利用し、比較し、改善案を考えられるコードとして公開されたからだ。
一方で、過度な期待も禁物だ。公開されたのは完成済みの全国自治体向けSaaSではない。内部データも、実際の行政RAGの知識ベースも、政府職員の利用ログも、LLM本体も公開されていない。導入にはクラウド技術とセキュリティ運用が必要で、ASL対象ファイルなどライセンス上の注意点もある。
それでも、これまで各自治体・各ベンダーがばらばらに作っていた「職員向けAI基盤」の共通部品が、政府の参照実装として公開された意義は大きい。今後の焦点は、このコードを各組織がどこまで安全に実装できるか、民間がどれだけ実務に即したAIアプリを作れるか、そしてデジタル庁がどこまで運用知見・技術記事・追加実装を公開していくかに移る。
まとめ
源内のソースコード公開は、「政府AIの中身がすべて公開された」という話ではない。正確には、政府職員向け生成AI利用基盤のWebインターフェースと、一部の行政実務用AIアプリ実装・開発テンプレートが、商用利用可能なライセンスで公開されたという出来事である。
だが、その意味は小さくない。行政AIのUI、外部AIアプリ連携、RAG、法令検索、LLMセルフデプロイ、認証、ログ、チーム管理といった要素が、具体的なコードとドキュメントで示された。これは、自治体にとっては重複開発を避ける材料になり、民間企業にとっては行政AIサービス市場に参入する足場になり、政府にとってはAI活用の標準化と官民共創を進めるための基盤になる。
今回の公開は、行政AIの「完成品」ではなく「出発点」だ。真価は、このコードをもとに自治体・企業・研究機関がどれだけ安全で実用的なAIアプリを作り、現場の業務改善につなげられるかで決まる。
出典
一次情報・参考リンク
- デジタル庁: ガバメントAI「源内」をOSSとして公開しました https://www.digital.go.jp/news/907c8e5d-2f4f-4bd7-9400-37c9f4221d7d
- デジタル庁note: ガバメントAI「源内」をオープンソースとして公開します https://digital-gov.note.jp/n/n84aeba282e60
- デジタル庁: ガバメントAI「源内」政策ページ https://www.digital.go.jp/policies/genai
- GitHub: digital-go-jp/genai-web (源内Web) https://github.com/digital-go-jp/genai-web
- GitHub: digital-go-jp/genai-ai-api (源内AIアプリ) https://github.com/digital-go-jp/genai-ai-api
- デジタル庁: ガバメントAIで試用する国内LLMの公募結果 https://www.digital.go.jp/news/10d55c63-b3e1-42b9-9cc5-93a06943ae0e
関連して読む
- · 参考リンク 6件
源内のLawsy実装をMCP化するなら、どこを残してどこを捨てるべきか
源内AIアプリのLawsy-Custom-BQを読み、低コストな日本法令MCPとして再構成する場合の設計境界、MVP機能、データ更新、リスクを整理します。
ローカルLLMが日本語実務でやらかす失敗集 — 実測7例ギャラリー
J-WorkBench の生トランスクリプトから、ローカルLLMが日本語の実務でやらかした失敗を7例そのまま並べた見本帳。JSON崩壊・根拠なし断言・敬語崩壊・表の二重計上・コード未修正、そしてローカルがクラウド3社に勝った逆転例まで、脚色なしの出力で示します。
ローカルLLMはクラウドの何割を肩代わりできるか — J-WorkBench クラウド代替率
日本語の実務7カテゴリで、手元PC(RTX 3090)のローカルLLMがサブスク版クラウドの何割を代替できるかを5軸で測ったベンチ J-WorkBench の実測結果。代替率66〜87%の正直な内訳、互角と苦戦の境界、向く/向かないケースを整理します。